

【行业聚焦】提升规土行业数字化质量建设之道

在规土行业中,存在结构化数据与非结构化数据并存的情况。针对非结构化数据我们需要对数据进行规范命名、数据过滤等,针对结构化数据需要对数据进行数据接入、数据清洗、数据治理等步骤。数据的融合、合并、过滤是数据处理中经常会遇到的问题。在数据量比较少的时候,手动测试勉强可以。但数据量一旦增多,再靠手动、人工就不太合适。毕竟,长时间从事重复性的劳动,人难免会出错,利用工具处理数据的重要性显而易见。作为规土行业信息化建设商,南康科技从四个方面总结出如何不断分析数据、反复处理保证提升数据质量的方法。
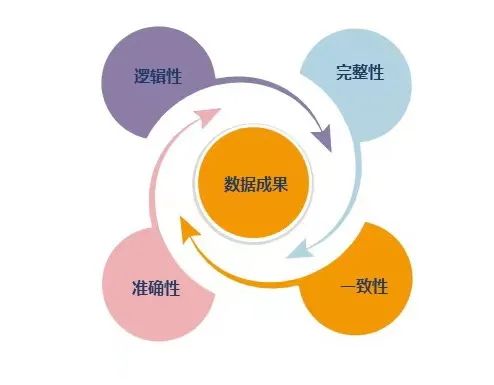
拿到数据之后,首先需要确认是否是全量数据,是否有遗漏、缺失。数据的完整,不仅要求其自身完整,还要保持整体的完整。自身完整是指数据的必填字段不为空,整体完整是指数据之间应连续、无遗漏。对于空间数据而言,数据应能完全覆盖研究区域,没有缺失。
对空间数据而言,准确性主要包括属性信息与图形信息的准确性。从空间上看,首先要检查的是图形的坐标系是否准确,其次是空间上有没有拓扑问题、自相交等其他检查项。从属性上看,首先要检查的是数据的表结构是否准确,然后检查数据的内容是不是准确,比如数据是否规范、全角半角字符等问题。
一般,数据有自身的逻辑,可以是单个数据集本身的关系,也可是多个数据集之间的关系,甚至单条要素的单个字段,都会有一些逻辑关系。我们用一块地的四至范围为例,如果将宗地细分为地块范围和四至范围,并将其分别存储在数据库里,地块表与四至表之间的逻辑需要满足一对四的关系。

某项目案例建设目的是为收集、梳理和规划土地数据提供契机,弥补数据缺失和不完善的情况,同时保证数据的完整性和准确性。南康科技项目小组利用业务地块空间位置上的层层串联,以业务轴的形式展现了该地块的全生命周期情况。其中涉及到的数据来源广且处理过程繁杂,有6张图形表和8张属性表,总数据量15万多条。项目小组采用搭建数据处理模型方式进行处理,实现了一键执行、多级检测的基本目标。该处理方式调整便捷、复用率高、易于实施推广。本项目共使用了9个数据处理模型,可以一键完成图形碎步检查、局部狭长检查、密度检查、图形融合、属性挂接等数据处理工作。项目模型的搭建为项目的顺利完成及后续运维提供了重要支持与保障。

数字化背景下,面对纷繁复杂而又分散割裂的海量数据,搭建数据处理模型有助于在打破数据孤岛的基础上,解决数据处理运维难、成本高的问题。南康科技的解决方案以多视角控制数据质量,从业务角度出发,“明确需求,对症下药”,全面提升数据的完整性、一致性、准确性、逻辑性,提升规土行业数字化质量建设。未来,南康科技将一如既往,为客户提供更精准、更快速、更满意的解决方案,助力规土行业数字化转型!



